如何呈現文字的意義
- 常見用法:準備字典去尋找對應意義或同義詞
單字離散化的問題:
- 無法區分「同義詞」之間中的一些細微差別
錯失尚未增進字典裏面的字詞,若需要修改會需要大量人力
電腦很難計算兩個字詞的相似性
主流統計方式的NLP,將單字視為「原子性」(atomic)的符號,以"one-hot"的方式表現,如下圖。
- 缺點 1:隨著單字的數量越大,維度跟浪費的空間也越多
- 缺點 2:相似詞或相關詞無法被搜尋到,因為沒有算法可以算出 "one-hot" 格式的兩個字的相似度(每個單字都是線性獨立的)

切入點 - 分布相似性 (distributional similarity)
- 透過句子結構中鄰近的單字,來補充相同或相似的單字 → 這也是現代統計性 NLP 蠻有效的方法之一
- 近期有個更簡單更快的模型: "word2vec"
word2vec 的主要想法
- 預測每個文字與他的內文的關係
兩個演算法:
Skip-grams (SG):
- 預測以「特定文字」為中心裡,在兩側(限定範圍內)出現某單字的機率為何
- 目標函數 - :求
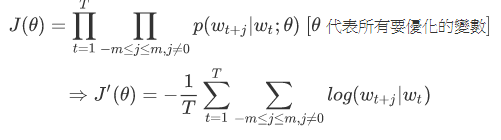
- 機率函數 - :這邊使用的是 Softmax 求機率
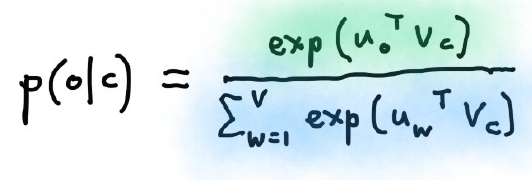
- 單字向量 - :讓所有模型裡面的變量都放在一個長的向量裡, 為位於中心文字的向量, 為位於內文文字的向量。
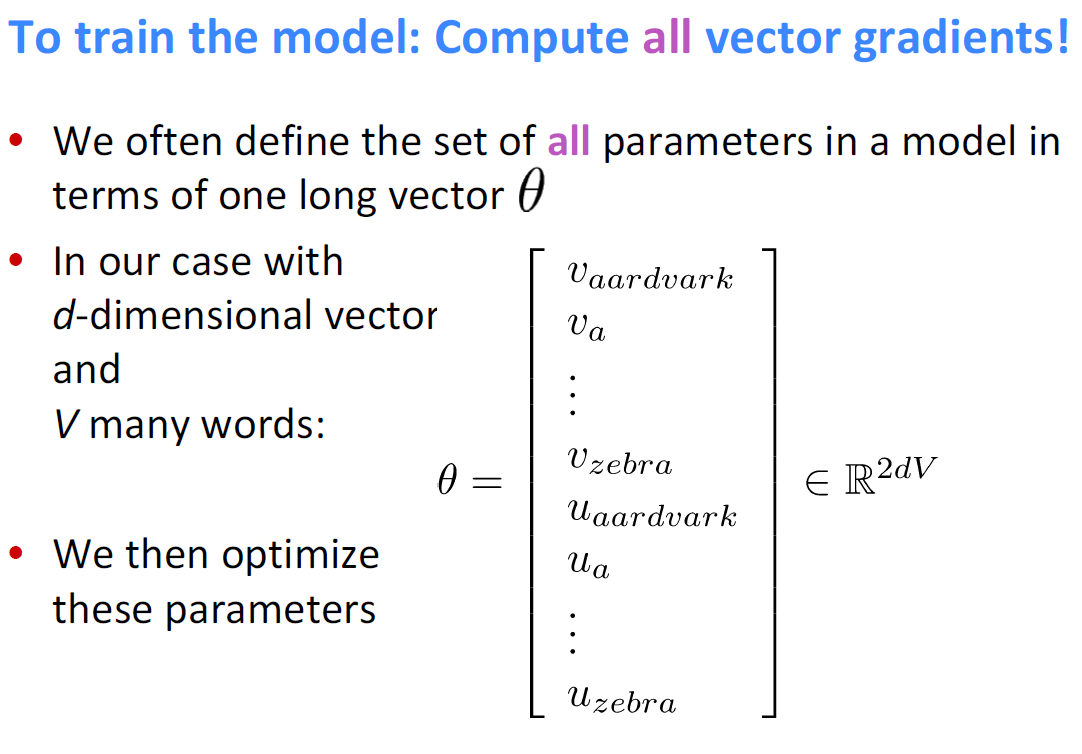
Gradient 推導過程



Stochastic Gradients Descent(SGD):將多次的運算結果加總再更新
- 可平行化:加快運算的速度
- 空間使用率:每次的結果最多只有 2m+1 個非零值,非常稀疏 (sparse)
- 解法:回傳特定欄數的資料,或是用 Hash 來儲存向量

Word2vec 透過將相似詞在向量空間中聚在一起,進而改進目標函數
Co-occurence matrix
- 以上方式是運算同時間出現的單字,而 Co-occurence matrix,就是單單統計在範圍中同時出現的文字組合
缺點:隨著單字量的增加,要更多儲存空間,但儲存的內容很稀疏 (sparse) → 分類的模型會比較不 robust
- 解法:只儲存最重要的幾個單字,儲存成新的且密集的(dense)向量 → 通常是 25-1000 維度
- 降維:使用 SVD
- 缺點 1.:nxm的矩陣的運算量為 ,若有百萬單字以上,複雜度太高
- 缺點 2.:若有新單字加入,難以擴充